Table of Contents
Introduction
NFV is a term that has been around for a few years now. As vendors and the open source communities look to drive the adoption of NFV, a wave of new acronyms and buzzwords are spreading through the industry. Within this article we will look into the various NFV components (such as standards, platforms, and acceleration technologies) required to build an NFV system.
What is NFV?
First of all – what is NFV?
NFV (Network Function Virtualization) is the concept of taking network functions that currently run on physical hardware (such as firewalls, routers and load balancers) and virtualizing them upon standard commodity hardware.
Advantages
NFV brings a number of advantages, in terms of both OPEX (operational expenditure) and CAPEX (capital expenditure). They include,
- Purchasing – Purchasing lines can be reduced and simplified, as the purchasing of various networking hardware lines from a range of vendors can be negated. Instead you can look to use your standard x86 server vendors to host your VNF’s (Virtual Network Function).
- Scaling – Provides greater flexibility in terms of vertical or horizontal scaling as the VNF can be instantly built.
- Provisioning – Compared to the time to purchase and cable a physical server, the provisioning times are greatly reduced.
- Power/Cooling – Because multiple VNFs can be run on a single server, the cooling and power consumption are greatly reduced.
- Licensing – In some instances, the license for a VNF will be cheaper compared to that of its physical counterpart.
- Hardware EOL’s – Due to decoupling the software from hardware, no physical network hardware will be required. This means you are not tied to the various EOL/product lifecycles of the vendors and the costly projects involved in hardware refreshes.
Frameworks and Standards
ETSI NFV ISG
The European Telecommunications Standards Institute (ETSI) is an independent, not-for-profit, standardization organization in the telecommunications industry.
In November 2012, the NFV Industry Specification Group (ISG) was formed to develop the required standards for NFV as well as sharing their experiences of NFV implementation and testing.[1]
There are two leading ETSI NFV Group Specifications (GS) – NFV Architectural Framework and NFV Management and Orchestration.
NFV Architectural Framework
The ETSI NFV ISG Architectural Framework (ETSI GS NFV 002) standardizes NFV by defining the various elements required in virtualizing networking functions. This framework contains two main sections – the High-Level NFV Framework and the Reference Architectural Framework.
High-Level NFV Framework – This framework describes, at a high level, the implementation of Network Functions on physical and virtual infrastructure. This is based upon three NFV working domains:
- VNF (Virtual Network Function) – A software implementation of a network function which is capable of running on top of the NFVI.
- NFVI (NFV Infrastructure) – A set of resources (physical or virtual) used to host and connect VNFs, such as compute, storage, or networking.
- NFV Management and Orchestration (MANO) – Covers the management and orchestration necessary for provisioning VNFs, along with their life cycle management.
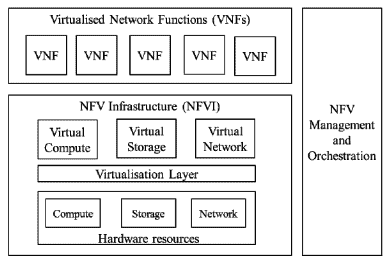
Figure 1 – High-level NFV Framework.[2]
NFV Reference Architectural Framework – This framework extends the previously mentioned High-Level NFV Framework. It focuses further on functional blocks, their interactions, and the changes that may occur within the operator’s network as a result of the virtualization of networking functions.
Along with the new functional blocks within the Management and Orchestration domain (explained further within the next section), we can also see the addition of the OSS/BSS and also the EMS*, and how they link to the other NFV working domains.
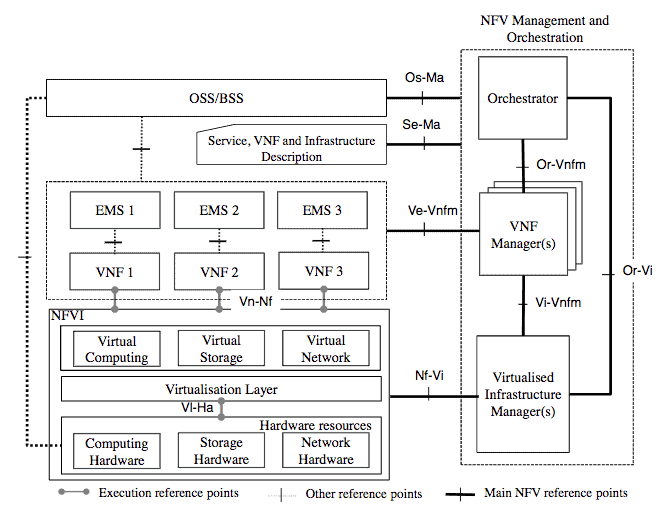
Figure 2 – ETSI NFV Architecture.[3]
* The definition of terms for OSS/BSS and EMS are shown below,
- OSS (Operational Support Systems) – In telecommunications, software (occasionally hardware) applications that support back-office activities which operate, provision, and maintain the communication network.
- BSS (Business Support Systems) – In telecommunications, software applications that support customer-facing activities: billing, order management, customer relationship management, and call centre automation.[4]
- EMS (Element Management System) – Performs management (configuration, alarm administration, etc) to a single or group of similar nodes.
NFV Management and Orchestration (MANO)
The NFV Management and Orchestration (also known as MANO) Group Specification defines a framework for how VNFs are provisioned, their configuration, and also the deployment of the infrastructure upon it will run.
Components
MANO is built around Entities, Descriptor Files, Repositories, and Functional Blocks.
Entities
Entities are the fundamental elements that form an ETSI MANO based environment.
- Virtual Deployment Unit (VDU) – Represents the VM that will host your virtual function.
- Virtual link (VL) – Provides connectivity between VNFs.
- Connection Point (CP) – The corresponding connection points for the virtual links.
- Network Service (NS) – A set of VNFs, VNF Forwarding Graphs, Virtual Links (VL), and Connection Points (CP) that together form a ‘network service’.
- VNF Forwarding Graph (VNFFG) – One or more forwarding paths across VNFs via either a single or set of Virtual Links (VL)/Connection Points (CP).
- Virtual Network Function (VNF) – Virtualized task formerly carried out by proprietary, dedicated hardware.
- Physical Network Function (PNF) – Purpose built hardware that provides a specific networking function, i.e. firewall.
Descriptor Files
For each element there is a descriptor file, i.e. a NSD, VNFD, VNFFGD, VLD, CPD etc. Each descriptor file describes the configuration parameters for the given Entity.
Repositories
Repositories hold information in ETSI MANO. There are four main repository types:
- NS Catalog – A repository of all usable Network Service Descriptors (NSD).
- VNF Catalog – A repository of all usable VNF Descriptors (VNFD).
- NFV Instances – Holds information of all VNF instances and Network Service instances.
- NFVI Resources – A repository of utilized NFVI resources for running Entities.
Functional Blocks
Finally, in order to orchestrate all of the above, NFV MANO is built upon 3 functional blocks:
- NFV Orchestrator (NFVO) – Onboards new Network Service (NS), VNFFGs, and VNF packages. Authorizes and validates NFVI resource requests. Along with manages the NS lifecycle, and performs validation/authorization of NFVI requests.
- VNF Manager (VNFM) – Is responsible for the life cycle of VNFs, such as the creation and termination, along with the FCAPS (Fault, Configuration, Accounting, Performance and Security Management).
- Virtualized Infrastructure Manager (VIM) – Controls and manages the NFVI (Network Function Virtualization Infrastructure) such as the virtual/physical compute, storage, and networking resources. Along with collecting events and performance metrics. Example VIMs are VMware, OpenStack and CloudStack.
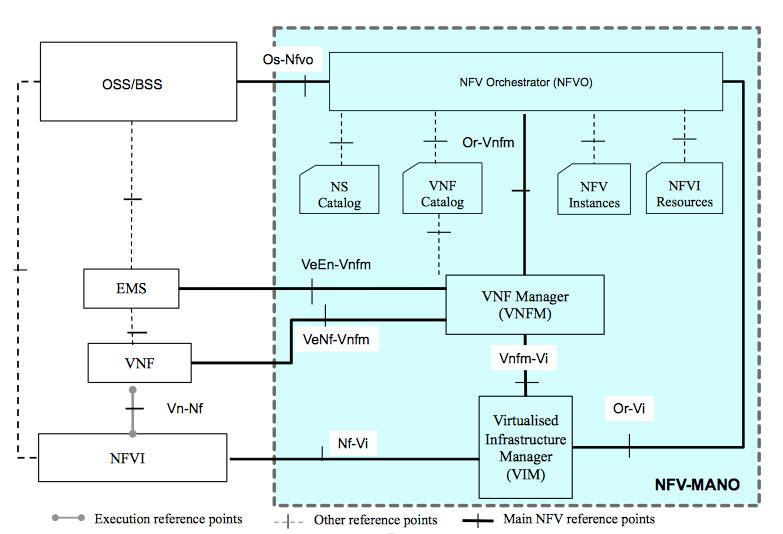
Figure 3 – The ETSI MANO model.
NOTE The specifications of each of the reference points between the three main MANO components can be located within the ETSI GS NFV-IFA 006-008 documents. This standardization of reference points allows interoperability when building multi-vendor ETSI MANO platforms.
Modelling
OASIS TOSCA
Topology and Orchestration Specification for Cloud Applications (TOSCA), is an OASIS standard language to describe a topology of cloud based web services, their components, relationships, and the processes that manage them.[5] This in turn provides portability and agnostic automation management across cloud providers regardless of underlying platform or infrastructure.[6]
Or in other words, TOSCA allows you to model an entire application into a single template, and then use it to deploy your application across 3rd party infrastructures (i.e cloud).
Components
So how does TOSCA model an entire application?
We start with a Service Template (Figure 4). A Service Template is used to specify the structure (Topology Template) and orchestration (Plans) of the application.
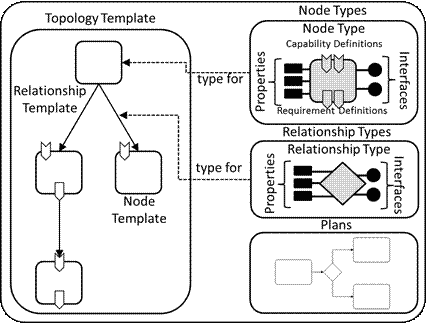
Figure 4 – Structural overview of a Service Template.[7]
Next, we have Node Types and Relationship Types.
- Node Types – A component within the Topology such as Compute, Database, Network etc.
- Relationship Types – Describes how nodes are connected to one another.
Both Node Type and Relationship Type contain Properties and Interfaces.
- Properties – Properties of the Node Type. i.e if the Node Type is Compute, then the properties would include RAM, CPUs, disk, etc.
- Interfaces – This is an entry point used by the TOSCA orchestrator to perform operations (such as lifecycle operations like “deploy,” “patch,” “scale-out,” etc.)
Now that we have the building blocks, the Topology Template can be built. This is built from Node Templates and Relationship Templates. A Template is an instance of a Type, i.e. the Node Template (instance) is an occurrence of a Node Type (class).
In addition, outside of the Service Template, there are Policies and Workflows.
- Policy – Defines a condition or a set of actions for a Node. The orchestrator evaluates the conditions within the Policy against events that trigger. The required actions are then performed against the corresponding Interfaces.
- Workflows – Allows you to define a set of manually defined tasks to run in a sequential order.
Finally, TOSCA supports a feature called substitution mapping. This basically allows you to take an entire Service Template and reuse it within another. For instance, Figure 5 shows an example via the reuse of the database.
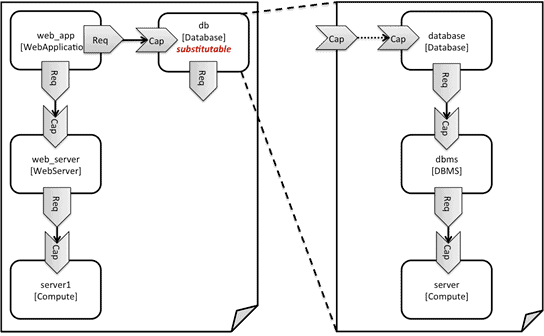
Figure 5 – Substitution Mapping.[8]
TOSCA NFV
You may be asking – How does this apply to NFV?
TOSCAs flexibility around re-usability (i.e substitution mapping) makes it ideal in describing network topologies. Not only this, but its ability to define Workflows (think VNF lifecycle) along with Policies (VNF monitoring/scaling) makes it extremely well suited to NFV.
In addition, TOSCA specifies a NFV specific data model, based upon ETSI MANO. This provides the ability to model the various entities within MANO, such as Network Services, VNFs, VNFFGs, etc.
Within Figure 6 we can see an example of a VNFD built using the TOSCA NFV standards. This VNFD would build a VNF with 1 vCPU, 512Mb RAM, 1Gb disk, along with a single management interface with anti-spoofing disabled.
tosca_definitions_version: tosca_simple_profile_for_nfv_1_0_0
metadata:
template_name: sample-tosca-vnfd
topology_template:
node_templates:
VDU1:
type: tosca.nodes.nfv.VDU.Tacker
capabilities:
nfv_compute:
properties:
num_cpus: 1
mem_size: 512 MB
disk_size: 1 GB
properties:
image: ciscoasa9.8
config: |
param0: key1
CP1:
type: tosca.nodes.nfv.CP.Tacker
properties:
management: true
order: 0
anti_spoofing_protection: false
requirements:
- virtualLink:
node: VL1
- virtualBinding:
node: VDU1
VL1:
type: tosca.nodes.nfv.VL
properties:
network_name: net_mgmt
Figure 6 – Simple TOSCA VNFD.[9]
SDN and NFV
Some of you may be asking, how does NFV differ from Software Defined Networking (SDN)?
To answer this, let’s look at the role that SDN provides. Software Defined Networking is the concept of separating the network control plane from the data plane. By decoupling the two it allows for a centralized model; this gives us a central point from which we can program the network but also centralize computation and management.
Let us look at the role of NFV. As we know, it is to abstract the network function from the underlying physical hardware to commodity based servers – we can see in one aspect SDN and NFV are the same, but in another – different. They BOTH seek to perform a level of network abstraction; however, the scope of their abstraction is somewhat different.
Even so, confusion can still be seen. Let us take the role of Service Function Chaining (SFC), which is a technique for selecting and performing traffic steering upon certain flows through a defined set of service functions. To perform this role, we would use SDN to program the control plane to steer the flows accordingly, right? But on the other hand, we are directing traffic through a set of VNFs via a set of descriptive expressions made via the NFV orchestration layer, such as the NFVO within an ETS MANO based model (explained in later chapters). Either way, it’s important to remember that conflicting topics such as these will certainly arise from time to time, especially based on the slew of SDN/NFV working groups and technologies currently in flight. However, we shouldn’t get too hung up on points. As long as we are clear on what, within the network, we are seeking to abstract, we can be clear of the key differences between NFV and SDN — SDN solves for control plane abstraction ; NFV solves for hardware abstraction.
Virtual Switches
Of course, the virtualization of networking functions is great, but of little use if you have no way to connect them to your virtual or physical networks. Because of this, virtual switches play an extremely important role in the world of NFV.
Within this section we will look at the Linux Bridge, OVS, and VPP virtual switching technologies.
Linux Bridge
The Linux Bridge is a kernel module, first introduced within 2.2, that provides software based switching. It provides layer 2 packet switching to multiple interfaces via the use of MAC forwarding tables, whilst also with supporting STP (Spanning Tree Protocol), 802.1Q VLAN tagging, and filtering. Filtering (at layer 2) is performed via ebtables, and/or iptables, for filtering higher network layers, such as layers 3 and 4.
Open Virtual Switch (OVS)
Open vSwitch is a multilayer software based switch. OVS was intended to meet the needs of the open source community, since there was no feature-rich virtual switch offering designed for Linux-based hypervisors, such as KVM and XEN[10]. Some of its key features include support for 802.1Q VLAN tagging, LACP, QoS, and various tunneling protocols (such as GRE, VXLAN, STT and LISP). In addition, OVS supports OpenFlow. This allows the flow of packets to be programmatically configured via the use of a controller, in turn making OVS the de facto standard virtual switching option within many SDN solutions.
When it comes to flow forwarding Open vSwitch forwards all new flows via userspace ovs-vswitchd (known as slow path), this allows northbound controllers to configure the Open vSwitch, via either,
- OVSDB – configures the OVS itself, such as creating, deleting and modifying ports, bridges and interfaces.[11]
OR
- OpenFlow – used to program flow entries.
Once a new flow has passed through ovs-vswitchd within userspace, the flow is cached within the kernel; any further flows are matched against the cache and forwarded by the OVS kernel data path – this is known as fast path.
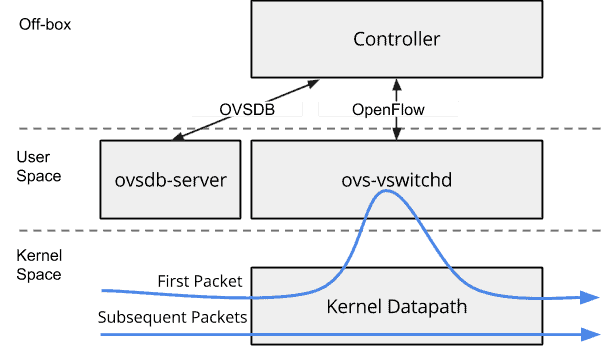
Figure 7 – The OpenFlow datapath.
OVS offers two deployment modes – Normal and Flow.
- Normal – Within normal mode, each OVS acts as a regular layer 2 learning switch, i.e. the source MAC address is learnt for each incoming frame against the ingress port. The frame is then either forwarded to the appropriate port based on the MAC address or flooded across all ports, if the MAC address has yet to be learnt or if it is a multicast or broadcast frame.
- Flow – Forwarding decisions are made using flows via the use of the OpenFlow protocol. Flows are received from a northbound API, aka controller (i.e control plane), and implemented into the Open vSwitches data plane. Further information on OpenFlow can be found here.
VPP
VPP (Vector Packet Processing) was originally created by Cisco and is now part of the FD.io project. It is a userspace application that runs on top of DPDK that provides high speed routing/switching. FD.io defines it this way:
The VPP platform is an extensible framework that provides out-of-the-box production quality switch/router functionality. It is the open source version of Cisco’s Vector Packet Processing (VPP) technology: a high performance, packet-processing stack that can run on commodity CPUs.
The benefits of this implementation of VPP are its high performance, proven technology, its modularity and flexibility, and rich feature set.[12]
In terms of its rich feature set, VPP provides support for a range of L2/L3 technologies such as (but not limited to) VXLAN, IPSEC, MPLS, VRF, ECMP, and L2 ACLs.
VPP runs as a userspace process, and is integrated with DPDK (covered within IO Optimization section) to provide an interrupt free, data path outside of kernel space.
But how does it work? VPP operates by processing a vector of packets through a Packet Processing graph (Figure 8). Instead of processing a single packet through the entire graph, the vector of packets is processed through a single graph node first. Once complete, they are then processed through the next graph node.
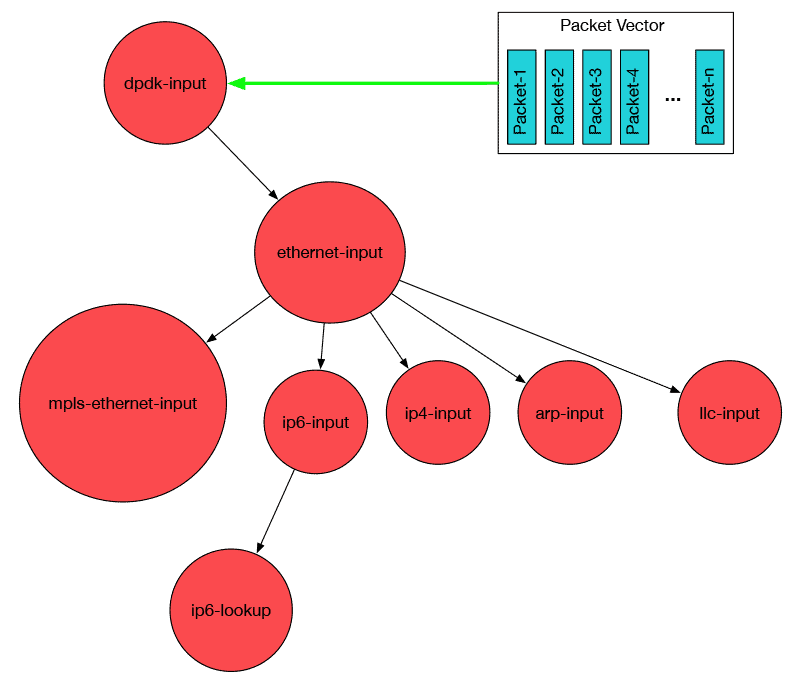
Figure 8 – VPP graph topology.[13]
The first packet in the vector spins up the cache; further packets are processed extremely quickly. One analogy to VPP is,
…consider the problem of a stack of lumber where each piece of lumber needs to be cut, sanded, and have holes drilled in it. You can only have one tool in your hand at a time (analogous to the instruction cache). You are going to finish cutting, sanding, and drilling the lumber faster if you first pick up the saw and do all of your cutting, then pick up the sander and do all of your sanding, and then pick up the drill and do all of your drilling. Picking up each tool in order for each piece of lumber is going to be much slower.[14]
In addition to the performance benefits that the VPP graph provides, it is also highly flexible in its ability to introduce new plugins and extensions.
Optimization
One of the key concerns when it comes to NFV is around performance, and that the network function you are virtualizing can deliver that of its hardware counterpart. However, with all the vendors competing to ensure their hardware based platforms are the fastest, through a range of dedicated based hardware, such as ASICs, FPGAs, crypto engines and SSL accelerators – can a virtualize instance really compete?
Within this section we will look at the various optimization techniques and technologies available within the industry that can be used to greatly enhance the performance of a virtual network function.
System Optimization
NUMA
Traditionally within a Symmetric Multiprocessor (SMP) machine, all CPUs within the system access the same memory. However, as CPU technologies have evolved and the performance of CPUs increased, so did the load upon the memory bus and the amount of time the CPU needs to wait for the data to arrive from memory.
NUMA (Non-Uniform Memory Access) addresses this by dividing the memory into multiple memory nodes (or cells), which are “local” to one or more CPUs.[15]
NUMA nodes are connected together via an interconnect, so all CPUs can still access all memory. While the memory bandwidth of the interconnect is typically faster than that of an individual node, it can still be overwhelmed by concurrent cross node traffic from many nodes.[16] So, though NUMA allows for faster memory access for CPUs accessing local memory nodes, access to remote memory nodes (via the interconnect) is slower, and here lies the need for NUMA topology awareness.
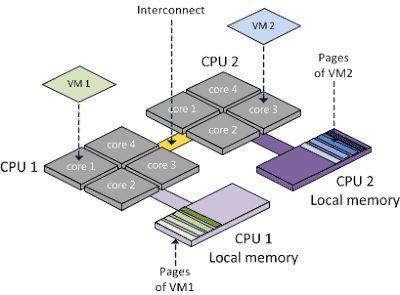
Figure 9 – NUMA based Memory Nodes.[17]
CPU Pinning
When the hypervisor virtualizes a guest’s vCPU, it is typically scheduled across any of the cores within the system. Of course, this behavior can lead to sub-optimal cache performance as virtual CPUs are scheduled between CPU cores within a NUMA node or worse, between NUMA nodes.[18] CPU pinning provides the ability to restrict which physical CPUs the virtual CPUs run on, in turn resulting in faster memory read and writes from the CPU.
Huge Paging
Within a system, processes work with virtual memory, also known as pages. The virtual memory is mapped to physical memory, and the mapping is stored within a data structure called a page table.
Each time a process accesses memory, a kernel translates the desired virtual memory address to a physical one by looking[19] into this page table. However, the page table is pretty complex and slow and we simply can’t parse the entire data structure every time some process accesses the memory.[20] Thankfully, CPUs contain hardware cache called the TLB (Translation Lookaside Buffer), which caches physical-to-virtual page mappings, speeding up lookups. However, the capacity of the TLB is limited; this is where huge pages come in. By increasing the size of the page, a larger amount of memory can be mapped within the TLB, reducing cache misses, and speeding up memory access times.
Let’s look at a simple example. Our example is based on the TLB having 512 entries.
| Page Size | TLB Entries | Map Size | Example | |
|---|---|---|---|---|
| Without Hugepages | 4096b | 512 | 2MB | 4096b * 512 = 2MB |
| With Hugepages | 2MB | 512 | 1GB | 2MB * 512 = 1GB |
I/O Optimization
Before we dive into the different packet optimization methods, let’s first take a look at some of the issues that can cause performance degradation, and in turn prevent a VNF from reaching the low latency 10Gb speeds required by today’s networks.
Based on Figure 10, we have a system with a virtual switch, along with a virtual instance. The hypervisor and Linux Bridge (i.e. a virtual switch) runs within kernel mode, with the virtual machine running within user mode.
Let us look at the flow, in further detail,
NIC to Linux Bridge – A frame is received by the NIC. It is moved directly into pre-allocated RX system memory buffers via DMA (Direct Memory Access). The NIC issues an interrupt request to the CPU, requesting the frame is moved from the RX memory buffer into the kernel stack. This is performed by the kernel driver.
Unfortunately hardware interrupts — in terms of CPU usage — are expensive ; they alert the CPU to a high-priority condition requiring the processor to suspend what it is currently doing, saving its state, and then initializing an interrupt handler to deal with the event.
Once the frame is within the kernel, it is processed through the network stack up to the Linux Bridge. However, the kernel network stack is inherently slow. It has to deal with a number of functions and protocols, from ARP to VXLAN, and it has to do it all securely.[21]
Linux Bridge to Virtual Instance – Once the frame has been received by the Linux bridge, and the necessary operations performed in order to determine that the packet is destined for our virtual machine, the kernel performs a system call.
The system call initiates a context switch. This switches the CPU to operate in a different address space. This allows our virtual instance, which is running within userspace, to ‘context switch’ to kernel space and retrieve the frame before returning to userspace so that it can further process the frame. Of course, this is hugely inefficient – in order to retrieve the packet, the virtual instance has to stop what it is doing for each IO request, not to mention the cost /overhead involved to perform the actual copying of data (/frame) between the two different address spaces.
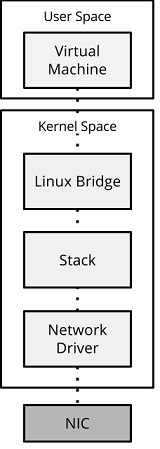
Figure 10 – Standard data path.
Even though this flow has been hugely simplified, it highlights that moving a frame through the kernel data-path and between system memory spaces is computationally expensive.
SRIOV
SR-IOV (Single Root I/O Virtualization) is an extension to the PCI Express (PCIe) specification. Virtual Functions (VF) are created that act like a separate physical NIC for each VM; the VF in the NIC is then given a descriptor that tells it where the user space memory, owned by the specific VM it serves, resides. This allows data to/from the NIC to be transferred to/from the VM directly via DMA (Direct Memory Access), bypassing the virtual switch, providing interrupt-free operation, and resulting in high-speed packet processing. However, there is a downside. Due the direct access between the VM and the VF, anything between, i.e. the virtual switch, is bypassed.
In addition to Virtual Functions, SR-IOV also provides the Physical Function (PF). Physical functions are fully featured PCIe functions that can be discovered, managed, and manipulated like any other PCIe device.[22] They contain the SR-IOV capability structure and manage the SR-IOV functionality, such as the setup and configuration on Virtual Functions.
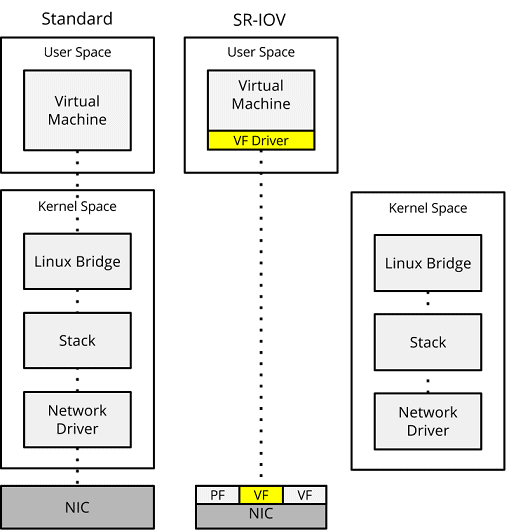
Figure 11 – Standard data path vs SR-IOV.
DPDK
DPDK (Data Plane Development Kit) is a framework (under the Linux Foundation) comprised of various userspace libraries and drivers for fast packet processing.[23] Originally developed by Intel to run on x86 based CPUs, DPDK now supports other CPU types, such as IBM POWER and ARM.
Though DPDK uses a number of techniques to optimize packet throughput, how it works (and the key to its performance) is based upon Fast-Path and PMD.
- Fast-Path (Kernel bypass) – A fast-path is created from the NIC to the application within user space, in turn, bypassing the kernel. This eliminates context switching when moving the frame between user space/kernel space. Additionally, further gains are also obtained by negating the kernel stack/network driver, and the performance penalties they introduce.
- Poll Mode Driver – Instead of the NIC raising an interrupt to the CPU when a frame is received, the CPU runs a poll mode driver (PMD) to constantly poll the NIC for new packets. However, this does mean that a CPU core must be dedicated and assigned to running PMD.
Additionally, the DPDK framework includes the following:
- Buffer Managers to optimize the allocation/deallocation of the network buffer queues.
- NUMA awareness to avoid expensive memory operations across memory nodes.
- Hugepages to optimize physical-to-virtual page mappings within the CPU’s TLB.
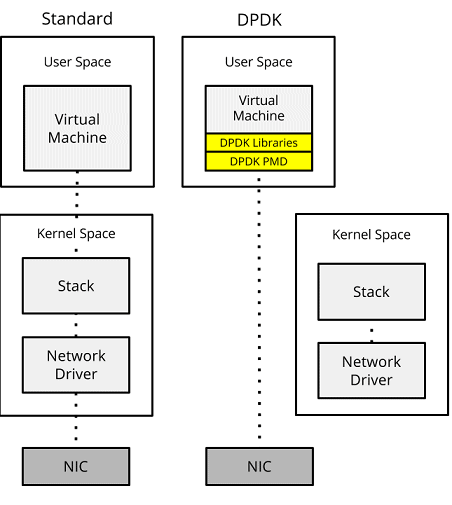
Figure 12 – Standard data path vs DPDK.
NOTE As well as the need for a DPDK supported CPU, a DPDK enabled networking adapter is also required.
OVS-DPDK
Out of the box OVS implements a kernel based data path, along with with a userspace daemon – ovs-vswitchd (Figure 13). This daemon processes new flows, allowing northbound controllers to programmatically update the control plane. However, this leads to a problem: even though the frame is cached within the kernel, it must be moved to userspace for processing by the virtual function. As we have already seen, context switching the frame between address spaces is expensive with regards to CPU cycles.
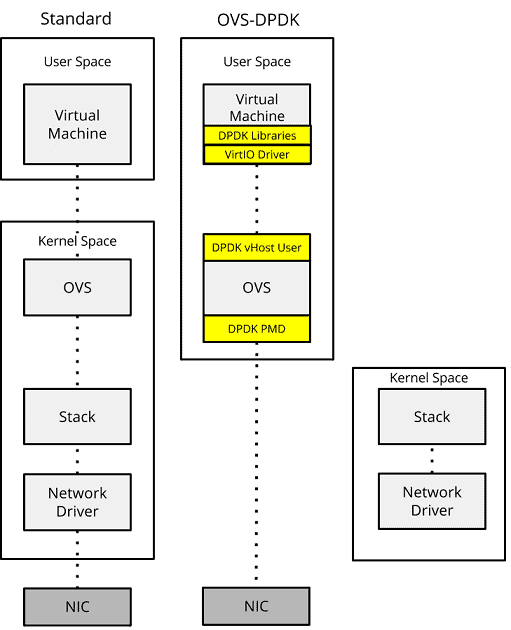
Figure 13 – Standard data path vs DPDK-OVS.
Open vSwitch (OVS) introduced DPDK support in OVS 2.2.
OVS-DPDK moves the OVS kernel data path into userspace. Frames are then retrieved directly from the NIC using a poll mode driver (PMD), allowing us to bypass the kernel.
With the frame and the VNF both now within userspace, further techniques can be used to move the frame between OVS and the VNF, such as vHost User.
vHost User is a driver, introduced within OVS 2.4.0, that allows QEMU (the virtualization software) to share with DPDK the memory location of the guests’ virtual queues. QEMU shares the memory allocations via the drivers’ backend implementations within OVS-DPDK. This allows OVS-DPDK to send and receive frames between the queues via DMA, resulting in a huge performance benefit.
Crypto Optimization
AES-NI
AES-NI (Advanced Encryption Standard New Instructions), originally initiated by Intel, is an extension to the x86 instruction set for Intel and AMD based CPUs. The purpose of the instruction set is to improve the speed of applications performing encryption and decryption using the Advanced Encryption Standard (AES).[24]
This allows you to accelerate crypto based VNFs, such as load balancers performing SSL termination, or IPSEC VPN gateways.
QuickAssist
Intel QuickAssist is an acceleration technology for compute-intensive functions such as cryptography and compression. Example use cases are,
- Symmetric cryptography functions, including cipher operations and authentication operations.
- Public key functions, including RSA, Diffie-Hellman, and elliptic curve cryptography.
- Compression and decompression functions.[25]
QuickAssist is integrated into the 27xx8 and 3xx8 Atom CPUs. Additionally, it is also built into the Intel Communications 8925 to 8955 Series chipset, allowing you to offload from your Intel based CPU.
Through an API, QuickAssist is exposed to the application (Figure 14). The APIs role is to interact with the Acceleration Driver Framework (ADF) and the Service Access Layer (SAL) who then in turn speak to the Acceleration Engine Firmware that resides upon the accelerations chip.
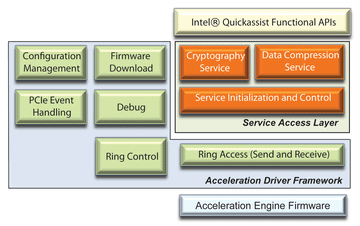
Figure 14 – Quick Assist driver architecture.
Projects
Standards and frameworks are terrific, but what good are they if there is no way to actually use them?
Within this section we will look at the leading open source projects, within the industry – looking at both ETSI MANO and full stack projects: ETSI MANO covering any or all of the roles within NFVO, VNFM, and the VIM; Fullstack with the entire stack including (and not limited to) data path technologies (i.e DPDK etc), virtual switching technologies (i.e OVS, VPP etc.), and SDN controllers.
ETSI MANO
Open Source MANO (OSM)
Open Source MANO is an ETSI-hosted project that provides an open source NFV MANO software stack. OSM is aligned with ETSI’s Industry Specification Group (ISG). Some of OSM’s key features include the following:
- Enhanced platform awareness (EPA) helps OpenStack assign VMs to run on the most appropriate platforms and gain additional benefits from features built into the system.[26]
- SDN underlay control guarantees bandwidth for each of the links when required.
- Multi VIM capability – supports multiple Virtual Infrastructure Managers, such as VMware and OpenStack.
- Multi-tenant VNFs – Ability to deploy and configure multi-tenant and single-tenant VNFs.
Open Baton
Open Baton is an ETSI NFV compliant MANO framework. On top of your typical MANO features, such as an NFVO and VNFM, Open Baton provides the following:
- Auto Scaling Engine allowing the ability to scale your VNFs.
- Fault Management System used for automatic management of faults.
- VIM Plugins for adding and removing different VIMs, without having to re-write anything in your orchestration logic.
- Zabbix Integration with the Zabbix monitoring system.
- VNFM Libraries that allow you to build your own VNFM.
OpenStack Tacker
Tacker is an official OpenStack project, based around the ETSI MANO Architectural Framework that provides VNFD Cataloging, VNF Provisioning, VNF Configuration Management, and VNF Monitoring and Auto Healing. Tacker provides the following:
- TOSCA Modeling – supports for describing the VNF via the use of TOSCA NFV templates that are then on-boarded to the Tacker VNF Catalog. VNFs are initiated by translating the TOSCA templates into OpenStack Heat.
- VNF Monitoring – performed via either an ICMP or a HTTP ping. If the VNF does not respond,, Tacker will Auto Heal by rebuilding the instance.
- VNF Configuration Management – performed via a configuration driver that vendors can develop against to allow VNF configurations to be pushed.
Full Stack
ONAP
ONAP (Open Network Automation Platform) is built upon the merging of AT&T’s ECOMP and China Mobile/Telecoms Open-O platforms. ONAP describes itself as,
… an open source software platform that delivers capabilities for the design, creation, orchestration, monitoring, and life cycle management of,
– Virtual Network Functions (VNFs)
– The carrier-scale Software Defined Networks (SDNs) that contain them
– Higher-level services that combine the above[27]
Each of the standard components of MANO, (VNFM, NFVO, etc.), are built out into a number of separate ONAP services and components to provide a range of rich features. ONAP provides all the features seen in Open Baton, Tacker, and OSM, whilst also providing a range of additional features including (but not limited to) the following components:
- Active and Available Inventory (AAI) – Provides real-time views of available Resources and Services and their relationships.[28]
- Master Service Orchestrator (MSO) – Arranges, sequences, and implements tasks based on rules and policies to coordinate the creation, modification, or removal of logical and physical resources in the managed environment.[29]
- Security Framework that allows for the security analysis of source code, vulnerability scanning, vulnerability patching, along with execution of policy based upon analytics and networking data from VNFs.
- Service Design and Creation (SDC) modeling/design tool, allowing you to define, catalog and build the required workflows (lifecycle management, activations etc.) for your VNFs.
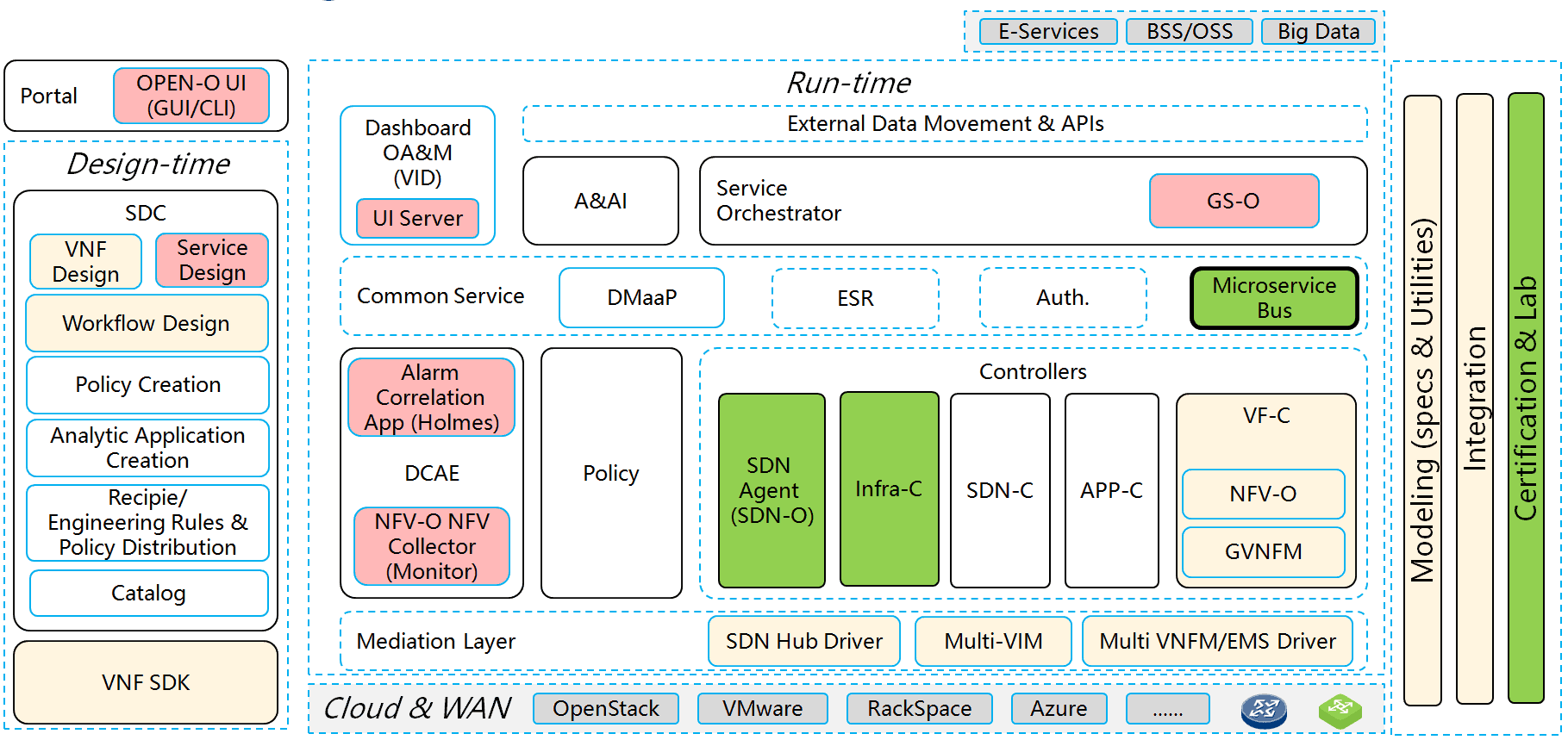
Figure 15 – ONAP Stack.
OPNFV
OPNFV (Open Platform NFV), is a Linux Foundation backed project aimed at integrating existing open source projects, such as OpenDaylight, ONOS, OpenStack, Ceph, KVM, Open vSwitch, and Linux, to provide a packaged and verified open source platform around NFV Infrastructure (NFVI) and Virtualized Infrastructure Management (VIM).
OPNFV works upstream with other open source communities to bring both contributions and learnings from its work directly to those communities in the form of blueprints, patches, and new code.[30]
In addition to the upstream contributions, OPNFV houses a number of projects, such as Doctor (VNF self healing) and Moon (security management), that leverage the various OPNFV components.
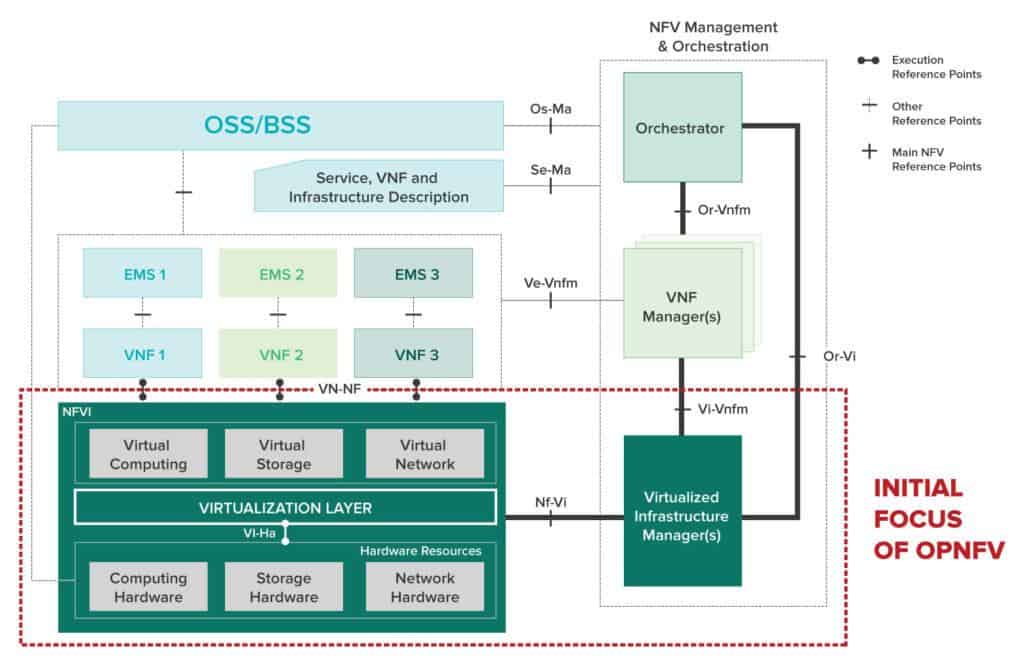
Figure 16 – OPNFV focus area.[31]
References
[1] “ETSI – NFV.” http://www.etsi.org/technologies-clusters/technologies/nfv. Accessed 22 Aug. 2017.
[2] “GS NFV 002 – V1.1.1 – Network Functions Virtualisation (NFV … – ETSI.” http://www.etsi.org/deliver/etsi_gs/nfv/001_099/002/01.01.01_60/gs_nfv002v010101p.pdf. Accessed 21 Aug. 2017.
[3] “GS NFV 002 – V1.1.1 – Network Functions Virtualisation (NFV … – ETSI.” http://www.etsi.org/deliver/etsi_gs/nfv/001_099/002/01.01.01_60/gs_nfv002v010101p.pdf. Accessed 21 Aug. 2017.
[4] “The Definition of OSS and BSS | OSS Line.” 5 Dec. 2010, http://www.ossline.com/2010/12/definition-oss-bss.html. Accessed 22 Aug. 2017.
[5] “OASIS TOSCA – Wikipedia.” https://en.wikipedia.org/wiki/OASIS_TOSCA. Accessed 21 Aug. 2017.
[6] “TOSCA – Oasis.” https://www.oasis-open.org/committees/tosca/faq.php. Accessed 22 Aug. 2017.
[7] “Topology and Orchestration Specification for Cloud … – Name – Oasis.” http://docs.oasis-open.org/tosca/TOSCA/v1.0/os/TOSCA-v1.0-os.html. Accessed 22 Aug. 2017.
[8] “TOSCA Simple Profile in YAML Version 1.0 – Name – Oasis.” http://docs.oasis-open.org/tosca/TOSCA-Simple-Profile-YAML/v1.0/csprd01/TOSCA-Simple-Profile-YAML-v1.0-csprd01.html. Accessed 24 Aug. 2017.
[9] “tacker/samples/tosca-templates/vnfd at master · openstack … – GitHub.” https://github.com/openstack/tacker/tree/master/samples/tosca-templates/vnfd. Accessed 24 Aug. 2017.
[10] “TripleO, NUMA and vCPU Pinning: Improving Guest … – StackHPC Ltd.” 3 Feb. 2017, https://www.stackhpc.com/tripleo-numa-vcpu-pinning.html. Accessed 24 Aug. 2017.
[11] “What is Open vSwitch Database or OVSDB? – Definition – SDxCentral.” https://www.sdxcentral.com/cloud/open-source/definitions/what-is-ovsdb/. Accessed 21 Aug. 2017.
[12] “VPP/What is VPP? – fd.io Developer Wiki.” 26 May. 2017, https://wiki.fd.io/view/VPP/What_is_VPP%3F. Accessed 21 Aug. 2017.
[13] “Technology – The Fast Data Project – FD.io.” https://fd.io/technology/. Accessed 24 Aug. 2017.
[14] “Technology – The Fast Data Project – FD.io.” https://fd.io/technology/. Accessed 21 Aug. 2017.
[15] “CPU Pinning and NUMA Awareness in OpenStack – Stratoscale.” 15 Jun. 2016, https://www.stratoscale.com/blog/openstack/cpu-pinning-and-numa-awareness/. Accessed 22 Aug. 2017.
[16] “Driving in the Fast Lane – CPU Pinning and NUMA Topology ….” 5 May. 2015, http://redhatstackblog.redhat.com/2015/05/05/cpu-pinning-and-numa-topology-awareness-in-openstack-compute/. Accessed 24 Aug. 2017.
[17] “OpenStack in Production: NUMA and CPU Pinning in High ….” 3 Aug. 2015, http://openstack-in-production.blogspot.co.uk/2015/08/numa-and-cpu-pinning-in-high-throughput.html. Accessed 21 Aug. 2017.
[18] “TripleO, NUMA and vCPU Pinning: Improving Guest … – StackHPC Ltd.” 3 Feb. 2017, https://www.stackhpc.com/tripleo-numa-vcpu-pinning.html. Accessed 24 Aug. 2017.
[19] “Mirantis OpenStack 7.0 NFVI Deployment Guide: Huge pages.” 25 Jan. 2016, https://www.mirantis.com/blog/mirantis-openstack-7-0-nfvi-deployment-guide-huge-pages/. Accessed 24 Aug. 2017.
[20] “Advantages and disadvantages of hugepages – TechOverflow.” 18 Feb. 2017, https://techoverflow.net/2017/02/18/advantages-and-disadvantages-of-hugepages/. Accessed 24 Aug. 2017.
[21] “Pushing the Limits of Kernel Networking – Red Hat Enterprise Linux Blog.” 29 Sep. 2015, http://rhelblog.redhat.com/2015/09/29/pushing-the-limits-of-kernel-networking/. Accessed 22 Aug. 2017.
[22] “Using PCIe SR-IOV Virtual Functions – Oracle VM Server for SPARC ….” https://docs.oracle.com/cd/E35434_01/html/E23807/usingsriov.html. Accessed 21 Aug. 2017.
[23] “DPDK.org.” http://dpdk.org/. Accessed 21 Aug. 2017.
[24] “AES instruction set – Wikipedia.” https://en.wikipedia.org/wiki/AES_instruction_set. Accessed 21 Aug. 2017.
[25] “Intel Quickassist » ADMIN Magazine.” http://www.admin-magazine.com/Archive/2016/33/Boosting-Performance-with-Intel-s-QuickAssist-Technology. Accessed 21 Aug. 2017.
[26] “Openstack Enhanced Platform Awareness – Intel Open Source ….” https://01.org/sites/default/files/page/openstack-epa_wp_fin.pdf. Accessed 24 Aug. 2017.
[27] “What is ONAP? – Developer Wiki – Confluence.” 18 Jul. 2017, https://wiki.onap.org/pages/viewpage.action?pageId=1015843. Accessed 25 Aug. 2017.
[28] “Active and Available Inventory (AAI) – Developer Wiki – ONAP.” 13 Apr. 2017, https://wiki.onap.org/pages/viewpage.action?pageId=1015836. Accessed 25 Aug. 2017.
[29] “Master Service Orchestrator (MSO) – Developer Wiki – ONAP.” 13 Apr. 2017, https://wiki.onap.org/pages/viewpage.action?pageId=1015834. Accessed 25 Aug. 2017.
[30] “Learn the Mission – Mission – OPNFV.” https://www.opnfv.org/about/mission. Accessed 22 Aug. 2017.
[31] “Enabling the Transition: Introducing OPNFV, an integral step towards ….” https://www.opnfv.org/blog/2014/09/30/enabling-the-transition-introducing-opnfv-an-integral-step-towards-nfv-adoption. Accessed 21 Aug. 2017.

- NETCONF & YANG: Automate Network Configs via Python - April 2, 2026
- Palo Alto – How to Configure Your Next-Generation Firewall - April 2, 2026
- How to Harden Linux SSH: Keys, Fail2ban & Ciphers - March 1, 2026
Want to become a networking expert ?
Here is our hand-picked selection of the best courses you can find online:
Cisco CCNA Certification Gold Bootcamp
Complete Cyber Security Course – Network Security
Internet Security Deep Dive course
Python Pro Bootcamp
and our recommended certification practice exams:
Delta Practice Tests